Datasets¶
Dataset is a collection of images, PDFs, text documents, audio files, and videos.
Navigate to Datasets icon on the left navigation bar to view all the existing datasets.
Click the Create New Dataset button to initiate creating a new dataset.
Dataset Setup¶
Specify a name for the dataset and provide a relevant dataset Description.
Choose an appropriate dataset Type from the list of currently supported types provided below:
Dataset Type |
Project Type |
|---|---|
Image |
Object Detection, Bulk Image Classification, Classification |
Native PDF |
Named Entity Recognition(NER) , Classification |
Plain Text |
Named Entity Recognition(NER) , Classification |
Scanned (OCR) |
OCR, Comprehend NER |
Video |
Media Transcription , Classification |
Audio |
Media Transcription |
AWS Security¶
Tensoract Studio provides the choice to enforce authentication with an AWS account. You have the option to enable AWS credentials and can choose to specify an S3 location for item processing when working on annotation tasks
Use Global IAM Credentials: Using this option, Tensoract Studio leverages the global IAM credentials to authenticate to the S3 bucket.
AWS Credentials: In this option, you have the ability to configure their AWS Access Key, Secret Key, and Region within Tensoract Studio to enable authentication with AWS.
Role ARN: In this option, you specify the AWS Role ARN and External ID for Tensoract Studio to authenticate with AWS. This method is considered the most secure and recommended approach for authentication.
Along with all the above options, you need to specify the Intermediate S3 Path that Tensoract Studio will utilize for task processing.
Dataset Metadata¶
You can provide dataset metadata as label-value pairs. It helps in filtering datasets based on metadata attributes.
Upload files to Dataset¶
You have the capability to upload documents to the dataset for processing. The following list outlines the compatible file formats for different dataset types:
Scanned Documents (OCR) - The compatible file formats include .pdf, .jpg, .png, .jpeg, .tif, and .tiff.
Native PDF - The compatible file formats include .pdf.
Plain Text - The compatible file formats include .txt.
Image - The compatible file formats include .jpg,.png,.jpeg,.tif,.tiff.
Video - The compatible file formats include .mp4.
Audio - The compatible file formats include .wav,.mp3.
There are following ways to upload the documents into the dataset:
Select Files - You can upload compatible files from local workstation directly to the dataset.
Select Folder - You choose a folder for the upload process. Subsequently, the system will enlist the files that are compatible with the dataset.
Select From Cloud - You can upload files from S3 bucket. If AWS credentials are not set for the dataset, the system will prompt for them.
Select Manifest/CSV/Txt - You can upload a manifest, csv or txt file. The system will parse the file and extract the valid URLs, which will then be added to the list of dataset items.
Note
You can select a subfolder in the S3 bucket. The service will fetch all compatible files in the path and add them to the list of dataset items.
You have the flexibility to add both local files and S3 files to the same list for uploading. Additionally, they can provide the full file path of a specific file, such as s3://*/abc.pdf.
You can choose to Upload All Files, Upload Selected Files and Delete Selected Files.
Add Teams to Dataset¶
You can specify the collaborators who will be working on the dataset.
Add Team member - You can select the collaborators’s name/email and the desired role from the drop-down menu. Click the Add Collaborator button.
Delete Team member - Click x symbol against the team member to remove them from dataset.
To get a quick overview of the steps involved in creating a dataset, watch the following video:
Dataset Items¶
Tensoract Studio provides the following options to browse through the dataset items:
Filter Dataset Items - You can leverage the capabililty to filter datasets items based on labels and values to narrow down the results based on specific filter attributes. Following filters are available:
All Fields
Dataset Type - Type of Dataset
ItemId - Unique id for each dataset item.
Labels - Annotations from the Completed tasks in the project.
Name - Name of the dataset item/file.
State - State of the dataset items such as “Processing”, “Processing Error”, or “Deleted”.
Source - Source of dataset upload when the dataset contains both Local and S3 items.
Tags - Tags applied by Admins or Dataset Supervisors to dataset item.
Text Preview - Text contained within dataset item.
ProjectID - After annotators and reviewers have completed the task flow, the ProjectId filter is automatically added to the dataset.
Version - As new versions are created, Version filter is automatically updated.
Model Run - When model is invoke for the items, the corresponding filter is automatically added to the dataset. This filter is applied to ensure that the dataset reflects the specific items used during the model execution, facilitating easy filtering and retrieval of relevant data.
Additionally, if there is metadata associated with the dataset items, it will also be available in the filters dropdown.
In addition, following options available to refine the dataset item serach and narrow down the results based on specific attributes:
Sort by - Sort the filtered items in ascending or descending order.
GroundTruth - Filter based on a project as a groundtruth, after annotator and reviewer have completed the flow.
Image Size - The image scale can be adjusted to increase or decrease the size of the image.
Page Size - The page size scale can be adjusted to increase or decrease the size of the page.
Details (Visible/Hidden) - This control allows you to hide or unhide the available details within the item.
Controls (Visble/Hidden) - This control is associated with Image Dataset. This control allows you to hide or unhide RGB controls withi the items.
Dataset Items View¶
Hover Over (5 sec) should show zoomed image of the dataset item in iframe.
Single Click is for multi-selecting dataset items.
Double click will open detailed view of the dataset item.
Press and Hold Ctrl key and single click will copy the ItemId of the dataset item.
Dataset Actions¶
Dataset items page provides an “Action” button, featuring the following available options:
Export items - Export selected items, filtered items or the entire dataset. Users can also export dataset associated with the Groundthruth project. To see the details of export fo
Clone items to new dataset - Clone the items into a new dataset.
Add items to project - Admin can directly send items from the dataset to the desired project.
Create bookmark - Bookmark can be created for the dataset, to access the dataset in read-only mode.
Find similar items - Retrieve similar matches to a dataset item.
Delete items - Admin or Dataset Supervisors can delete the items.
Add tag - Tags can be added to items to select specific items in dataset.
Remove tag - Tags can be removed from the dataset items.
Run Model - The system will initiate predictions using the selected model.
For a quick overview of Dataset Actions, watch the following video:
Model Run¶
Model Run refers to the execution or application of a model to make predictions of labels or annotations.
In order to use Model Run in dataset, the model needs to be first registered in the studio. Refer to Model Management for more details.
You can choose and execute models, generating predictions for selected items. Admin can see Model View and compare Model runs.
In addition, you can compare the predictions generated from the model run with the projects available in Groundtruth Filters.
Within the detailed view of a dataset item, you can see the predicted labels from model run as well as the Groundtruth labels from project. The labels from model run that match with the labels from Groundtruth are displayed in green color, indicating consensus.
For a quick overview of model comparisons for an OCR dataset, watch the following video:
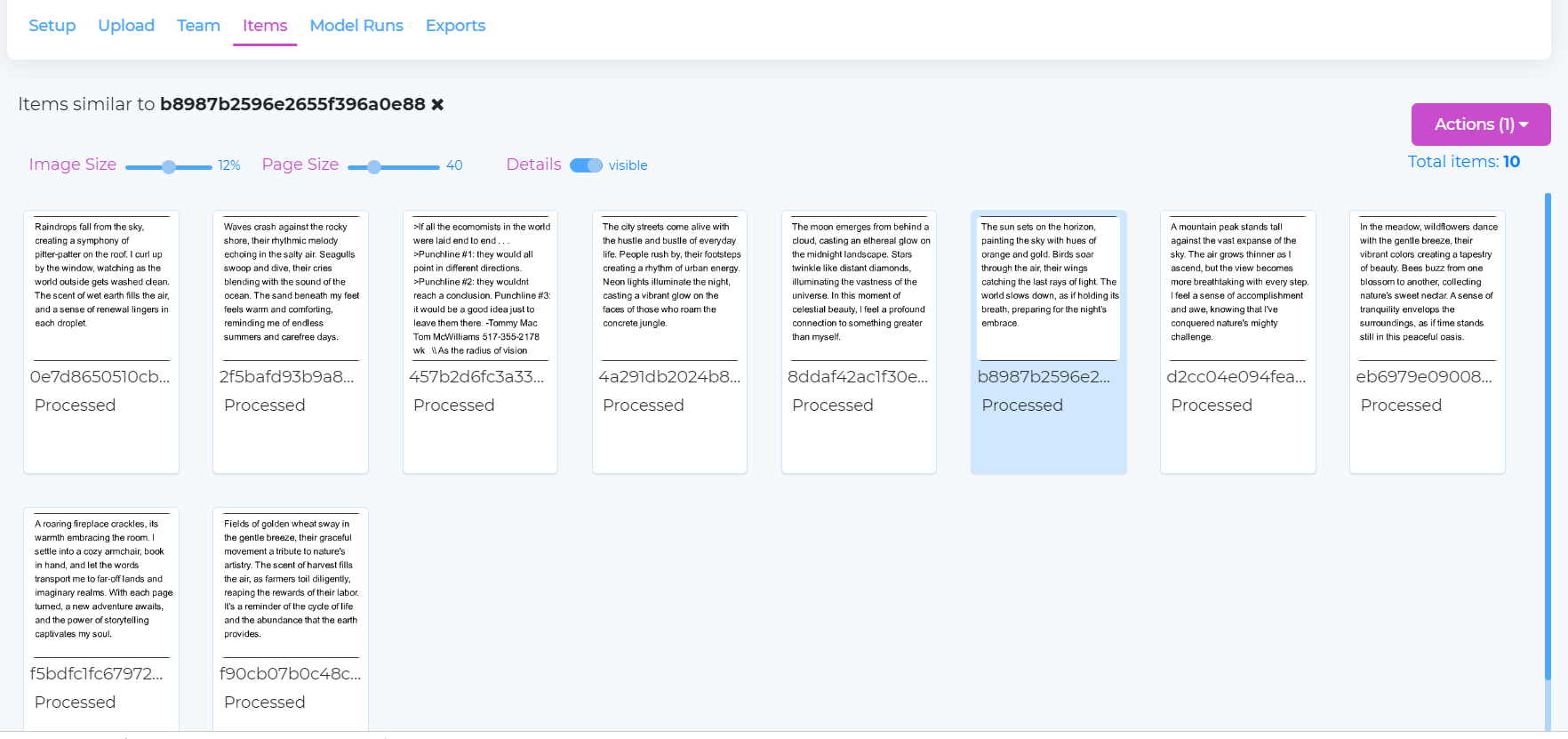
Find similar items¶
This functionality allows you to retrieve records or data items in a dataset that are conceptually similar or related to a given search query. You are required to have an embeddings model configured as described in the Model Management section. On dataset setup page, you have an option to enable and select the embeddings model. Tensoract Studio uses the selected embeddings model to search for similar items.
Once the embeddings model is enabled, you get an option to “Find similar items” among the available actions when you select a dataset item on the Items tab. You can enter the maximum number of items you want to retrive as similar.
The results are displayed as shown below.
Export¶
This sections shows a list of exports, that can also be downloaded by users.
Global Search¶
Global search is the overview of all datasets.This feature allows you to perform comprehensive searches across all Datsets. There are 2 ways to initiate a global search.
From the Datasets page.
From the Projects page, inside the Datasets tab.
You have an option to:
Apply filters: The Dataset type filter is pre-defined and cannot be modified. However, you have the flexibility to add additional filters to further refine your search.
Sort by: Sort the filtered items in ascending or descending order.
Filter based on GroundTruth: Filter based on a project as a groundtruth, after annotator and reviewer have completed the flow.
You can perform following actions after filtering the required dataset items:
Add Items to Project: Admin can directly send items from the Global Search to the desired project.
Add Tag: Tags can be added to items to select specific items in dataset.
Remove Tags: Tags can be removed from the dataset items.